Core Concepts and Terminology
Pelican is a tool for building data federations, a model in which decentralized, autonomous data repositories work together to make their data broadly available to other members of the federation under a minimally-centralized structure. In this model, data is accessed through a unified namespace regardless of where the data comes from or what type of storage is used to host it -- to a user, everything feels like it's coming from the same source.
Terminology
Objects
Pelican should be thought of as a tool that works with federated objects as opposed to files. The reason for this is that calling something a file carries with it the connotation of a filesystem. File systems have extra features such as owners, permissions, etc., which Pelican does not implement. In addition, a file gives the connotation that the file is mutable, i.e., its contents can change without requiring a new name. Objects in a Pelican federation, however, should be treated as immutable, especially in any case where objects are pulled through a cache (which will be the case for almost all files in the Open Science Data Federation (opens in a new tab), or OSDF). This is because the underlying cache mechanism, powered by XRootD (opens in a new tab), will deliver whatever object it already has access to; if an object's contents change at the origin, the cache will remain unaware and continue to deliver the old object. In the worst case, when the cache only has a partial object, it may attempt to combine its stale version with whatever exists at the origin. Use object names wisely!
Namespace Prefixes
Each origin supports one or more namespace prefixes, which are analogous to the folders or directories from your computer that you use to organize files. Below is an example object:
/demo/testfile.txtThis is a simple example where the namespace prefix would be /demo and the object is named /testfile.txt.
However, things can get a little tricky when you add a longer namespace prefix and/or a longer filepath within that namespace where the object lives. For example:
/ospool/uc-shared/public/OSG-Staff/validation/test.txtIn this example, the namespace prefix is /ospool/uc-shared/public/, and the actual object is named /OSG-Staff/validation/test.txt.
Differentiating Namespace Prefixes and Object Names
To discover where the namespace prefix ends and the object name begins, there are a few options. One way is to access your federation's registry (i.e. https://osdf-registry.osg-htc.org/view/registry/ (opens in a new tab)) which should list the namespaces available in the federation. Another option is also asking your federation administrator for how to access the registry. However, you can always think to just combine these two terms into just the "object's path" or the "path to the object within the federation".
Federations
Objects in Pelican belong to federations, which are aggregations of data that are exposed to other individuals in the federation. Each Pelican federation constitutes its own global namespace of objects and each object within a federation has its own path, much like files on a computer. Fetching any object from a federation requires at minimum two pieces of information: the federation's root (i.e. the discovery URL), and the path to the object within that federation (there is the potential that some objects require access tokens as well, but more on that later). For example, the OSDF’s federation hostname is osg-htc.org, an example path to an object in the federation is:
/ospool/uc-shared/public/OSG-Staff/validation/test.txtCombining these two pieces of information, we say the the object's URL is:
pelican://osg-htc.org/ospool/uc-shared/public/OSG-Staff/validation/test.txtCore Entities
Pelican federations consist of 6 core entities:
- Clients
- Data Repositories
- Origin Servers
- Cache Servers
- Central Services (the Director and Registry)
where each of these federation stakeholders represents a unique set of interests. One of Pelican's core functionalities is balancing the sometimes-competing needs of each of its constituents.
A description for each of these entities is provided below.
Clients
Pelican views itself as serving two types of users; data providers and data consumers. Pelican Clients are the tools built around Pelican that support consumers, enabling them to download data via a federation. Pelican currently has three Clients, and more are under development. Existing Clients include the Pelican CLI tool, the Pelican FSSpec (opens in a new tab) for Python, and a file transfer plugin for HTCondor (opens in a new tab).
Pelican Clients are designed to work with pelican://-style URLs, which defines a metadata lookup protocol on top of HTTP. For more information on this URL specification, see Pelican's client usage documentation.
Lastly, because Pelican builds on top of HTTP, most HTTP clients (e.g. curl) can be modified to interact with Pelican federations.
Data Repository
Data can live in any number of places, from a hard drive with an associated POSIX filesystem, to buckets in S3. Pelican defines a Data Repository as any instance of a storage backend.
Data Repositories often have their own policies that are unique from federation policies, including things like authentication/access control and rate limiting.
Pelican's primary goal with respect to Data Repositories is to make the data they hold accessible to clients within a federation, without requiring that users know what type of repository the data comes from or how it works.
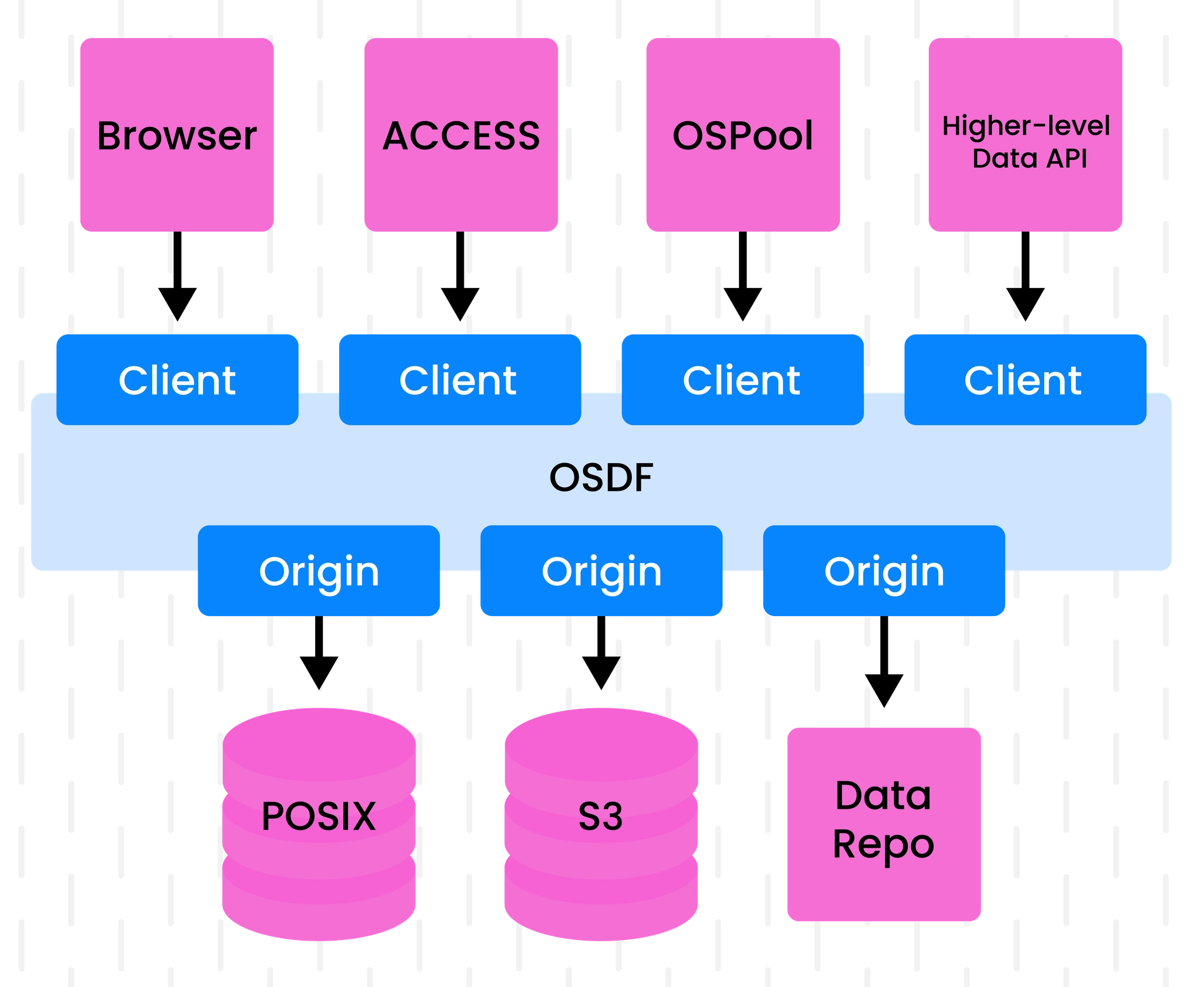
Origins
To make data from a Repository available through a Pelican federation, the data provider must serve an Origin in front of the Repository.
Origins are a crucial component of Pelican's architecture for two reasons: they act as an adapter between various storage backends and Pelican federations, and they provide fine-grained access controls for that data. That is, they figure out how to take data from wherever it lives and transform it into a format that the clients from the federation can utilize while respecting the Repository's data access requirements. This implies an inherent trust relationship between Origins and Data Repositories, as the Origin is responsible for enforcing the Repository's needs and wishes within the rest of the federation. However, while the Origin is responsible for translating the Repository's data access policies into something the federation can understand, Pelican is designed so that Origins never need to share secrets with their federation.
Pelican Origins work by making their underlying Repository accessible under some namespace path via HTTPs, which is accomplished by building on top of XRootD (opens in a new tab). The namespace path, also called the federation prefix, is the path at which data from the Origin can be accessed in the federation. For example, an Origin that exports the namespace path /foo might provide access to an object bar in the underlying Data Repository. The full path for this object in the federation would be /foo/bar.
NOTE: An important distinction between Origins and Data Repositories is that, generally speaking, Origins do NOT store any data themselves; their primary function is to facilitate data access from the Repository, which may not coincide on the same machine.
Pelican Origins serve as a transport bus, connecting a variety of backend storage types to their federation
Caches
Pelican Caches are responsible for storing copies of data inside the federation with the goal of providing more efficient access to reusable data. By default, requests to a Pelican federation for an object are proxied through a Cache, resulting in the federation storing a temporary copy of the object. Currently, objects are cleared from Caches based on a "least recently used" algorithm whenever the server begins running out of storage space, but more robust forms of cache management are in active development. Like Origins, Caches build on top of XRootD's "Proxy Storage Services." (opens in a new tab)
Because Caches store copies of data for re-distribution in the federation, they must also respect the Origin's data access policies. That is, the Origin should trust Caches to protect any data that isn't marked as publicly accessible. Caches in a Pelican federation accomplish this by aggregating access policies from the Origins they support and following the same approval/denial rules the Origins themselves would follow.
Generally, Caches are operated by the federation and placed close to computing clusters where data may be quickly re-used as part of High-Throughput Computing workflows, but this is not a requirement.
Central Services
It was mentioned that data federations operate under a minimally-centralized structure. In Pelican, this structure is made up of the Central Services, namely the Director and the Registry.
NOTE: Pelican's Central Services are responsible for connecting Data Repositories and data consumers, but a core part of Pelican's architecture is that objects never pass through the Central Services. In fact, the federation’s Central Services are unable to access any authorization-protected objects via Origins unless the Origin mints a token granting that permission. In this way, Origins that don’t allow their data to be staged/cached in the federation need not trust the federation operators, because each Origin acts as its own token issuer and is solely responsible for deciding which requests to respect. This architecture also prevents the creation of centralized bottlenecks as a federation grows.
Director Service
Data access in a Pelican federation requires two fundamental pieces of information -- the federation's hostname (also called the root of the federation), and the name of the object within the federation. Notably, the hostnames of any Origins that facilitate access to objects are absent from that list. Instead, the Pelican model uses the federation root to discover and route all Client requests for objects through its Director, an HTTP server whose job is determining the best location(s) at which to access a given object. In some cases, this is accomplished by redirecting clients to a nearby Cache that might already have a copy of the object, and in other cases the Director might send the client to an Origin that can provide direct access.
Generally, the Director's hostname is used as the federation's hostname because it auto-populates and makes available the federation's metadata. This information is hosted at the discovery endpoint, a URL obtained by appending /.well-known/pelican-configuration to the federation's root. However, some federations may wish to set up the Director/Registry as subdomains of the federation's hostname. For example, the OSDF breaks these two endpoints apart by providing federation metadata at osg-htc.org, which then points to osdf-director.osg-htc.org and osdf-registry.osg-htc.org, respectively.
All Origins and Caches in a federation send periodic advertisements to the discovered Director at a default interval of 1 minute to let it know where they can be accessed, which namespace(s) they provide, and any information pertaining to data access policies (such as authorization schemes). In this way, the Director is the only service that has a nearly real-time view of all the Origins and Caches in the federation -- if an Origin or Cache fails to re-advertise after the required period (15 minutes by default), it is assumed to be offline until another advertisement is received, and the Director will stop sending clients to that location.
Registry Service
Whenever a new Origin or Cache is created and added to a federation, its first step is to register itself with the Registry, which acts as the federation's locus of trust. In the case of Origins, the process of registration entails sending the Registry the namespace prefix the Origin exports, along with the Origin's public key and a variety of other bookkeeping information. After the Registry and the Origin have performed a handshake that proves the Origin owns the corresponding private key, the Registry stores the information in a persistent database.
This process serves two purposes -- first, whenever the Origin re-advertises with the federation's Director, the Director can verify the authenticity of those advertisements through public/private key asymmetric cryptography by looking at the Registry's stored public key for that Origin and namespace. Second, the Registry's persistent database prevents other Origins from registering namespaces under an already-registered namespace without first proving they're allowed to do so by the namespace owner (i.e. the entity that possesses the appropriate private key).