Namespace Prefixes and How To Choose One
In “Romeo & Juliet”, William Shakespeare writes:
What’s in a name? That which we call a rose
By any other name would smell as sweet.
Unfortunately for us, Shakespeare’s wisdom doesn’t hold true in environments where names carry relational information or otherwise convey information about the named entity. That’s why picking a good federation prefix for Pelican is so important — it’s the data owner’s opportunity to say something about their data and to frame the way data consumers will think about the objects they access.
The process of organizing and naming data can be difficult. Even the Dewey Decimal System has gone through 23 major revisions over ~150 years and now comprises two entire volumes[1]. Luckily, there are some best practices that can lead to reasonable choices in picking a namespace.
The following sections contain advice about our best practices for organizing your data in Pelican, and understanding each section will help you pick namespaces that maximize the FAIR principles of your data.
Data Provenance and Taxonomy
One of the the best ways to start picking namespaces is to think about how your objects might be taxonomically structured. Taxonomy is the practice of organizing things into hierarchical categories based on their characteristics, relationships, and differences. Consider the following example:
CoolScienceOrg/
└── WhaleTrackingProject/
├── Atlantic/
│ ├── 2023/
│ │ ├── Jan/
│ │ │ ├── image1.jpg
│ │ │ └── ...
│ │ ├── Feb
│ │ └── ...
│ └── 2024
├── Pacific
└── ...If a user understands how to find one object under this namespace, they’ll likely understand how to find any object that fits the same naming scheme under this namespace by changing predictable keywords like ocean names, years and months.
Choosing these keywords is often unique to each project and highly dependent on the underlying data. However, one common technique to discover reasonable choices for keywords is to think about the terms you’d use to Google for certain objects or collections of your objects. In the previous example, one might imagine the user Googling something similar to:
whale sightings over time in the atlantic and pacific
This expresses some of the relationships inherent between individual objects in this data repository — data relates to whale sightings and is split over time and by ocean.
It’s also important to note that this example includes information highlighting the data’s provenance or where it came from and who’s responsible for it. More often than not, it’s a good idea that your namespace starts with something signifying your organization, group, or project. This is especially useful because Pelican namespaces are hierarchical and can be further subdivided (see the section on namespace delegation below for more information).
In the previous example, a namespace beginning with /CoolScienceOrg/WhaleProject lets users quickly attribute any data coming from this section of the federation to your
organization and project. If data consumers have questions about some object, this namespace prefix is likely enough for them to figure out who to ask for more information.
Lastly, this type of naming scheme makes the objects very interoperable for machine/workflow access because a simple nested for loop could be written to fetch every individual
image. The ability to create predictable naming conventions that integrate with large-scale computing workflows is crucial for data re-use.
Namespaces versus Object Names
The full “name” of any Pelican object comes from its Pelican URL, e.g.
pelican://osg-htc.com/this/is/an/object
which tells Pelican clients what federation to work with and how to find the actual object.
Because Origins map namespace/federation prefixes to sections of the underlying data repository, it can be confusing to understand where the namespace ends and the
object begins in a path like /this/is/an/object. Information about how to determine this split given a Pelican URL can be found in
Core Concepts. However, this presents a unique challenge to Origin
administrators, because they have to decide which parts of a Pelican object’s name should come from the federation prefix, and which should come from the underlying
object name as understood by the storage resource. Consider a posix filesystem with the following directory tree:
physics/
├── detector1/
│ ├── 2023/
│ │ ├── raw/
│ │ │ └── event.csv
│ │ └── processed/
│ │ └── event.csv
│ └── 2024/
│ └── ...
└── detector2/
└── ...The administrator who wishes to federate this data has several choices to make. For example, they could create federation prefixes with the following prefix-to-directory mapping:
/my-namespace/detector1 —> /physics/detector1
/my-namespace/detector2 —> /physics/detector2
which would expose detector1’s 2023/ and 2024/ directories under the prefix /my-namespace/detector1 and detector2’s directories under /my-namespace/detector2.
This is completely valid. However, they may also choose to scope things differently, creating the simple mapping:
/my-namespace —> /physics
where the entire contents of the /physics directory are exposed through the Pelican namespace prefix of /my-namespace. Choosing the right scoping level depends in part on
the administrators broader goals and needs.
Prefixes as a Means of Reorganization
Because namespace prefixes essentially map some path in a Pelican federation to underlying storage, they can be used for minor re-organizational tasks. For example, this filesystem has a series of poorly-named and poorly-organized directories:
/my-data/
├── grad-school-stuff/
│ ├── first-detector/
│ └── detector2/
└── jan2021/
└── detector-three/In this case, namespacing through Pelican may allow the Origin administrator to correct these issues without touching the underlying filesystem through the creation of a mapping like:
/particle-physics/detector1 —> /my-data/grad-school-stuff/first-detector
/particle-physics/detector2 —> /my-data/grad-school-stuff/detector2
/particle-physics/detector3 —> /my-data/jan2021/detector-three
To users, each event from these detectors will now follow a predictable access pattern when accessed via Pelican.
Prefixes as a Means of Delegated Management
Because prefixes are hierarchical entities in Pelican, they can be further subdivided by anyone who has the appropriate cryptographic keys. This means the “owner” of a namespace
can delegate sub-namespaces to other people in their group, even if the namespace itself isn’t exported through any origin. Because prefix registration can be done through the
Pelican independent of any origin, the head of “ProjectXYZ” may choose to create the top-level /project-xyz namespace with one set of keys. From here, they may use their
ownership of the top-level namespace to create a nested namespace like /project-xyz/johnson-lab tied to a separate set of keys that they give to the leader of the Johnson lab.
Johnson may then use his/her ownership of the sub-namespace to create further sub-namespaces for lab students. In this setup, each prefix owner has control over their section of
the namespace without having control over the parent namespaces.
Warning: One caveat here is that matching a namespace prefix will take precedence over any potential object names. That is, if the prefix
/project-xyz/johnson-lab/foois registered, then the origin exporting/project-xyz/johnson-labwill not be able to export objects that begin withfoo/.
Prefixes as a Means of Aggregating Disparate Repositories
One additional benefit of namespaces and the fact that they can be exported by multiple Origins is that they may allow data owners to aggregate data from multiple sources under a common name. For example, consider a case where you have two telescopes taking snapshots of the night sky. Due to each telescope’s technology, one saves its images in S3 and the other stores its images in posix. Namespacing allows the data owner to hide this fact from data consumers by exporting both the S3 bucket and the posix filesystem under the same namespace:
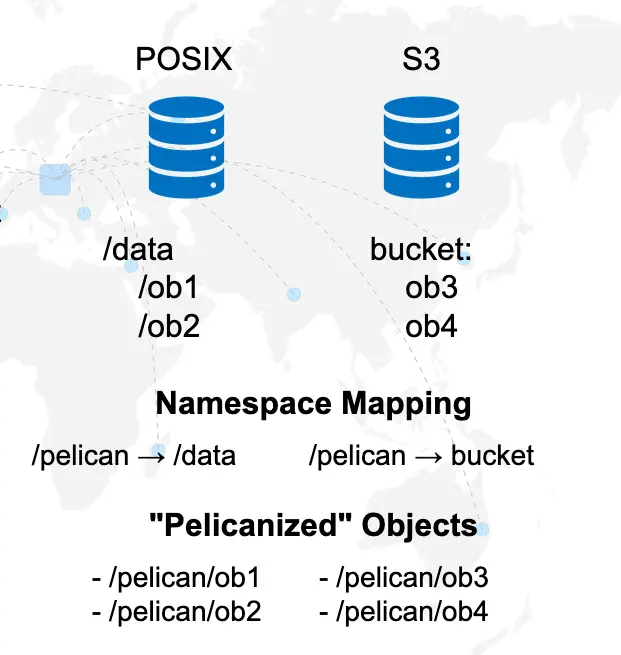
Namespace Prefix Restrictions
There are two categories of characters and character combinations that Pelican prohibits in namespace prefixes: those that are special in POSIX filepaths and those that are special inside URLs. In both cases, Pelican disallows these characters as a matter of design because they may cause issues with the way Pelican uses HTTP, or they may have unintended consequences when interacting with XRootD, where object names are treated like POSIX paths.
For example, the character sequence ../ in POSIX means “up one directory”, such that a filepath like /foo/bar/../baz is actually expanded to /foo/baz. This makes it
potentially unsafe to allow a prefix like /my-prefix/../, which when interpreted as a filepath is just /. Because of the special meaning given to these characters, and because
their use can lead to certain forms of computer attacks when handled incorrectly, Pelican disallows some characters and character combinations in prefixes.
Other top-level prefixes are restricted because Pelican uses them internally for things like origin/cache registration, or in monitoring.
The following table lists the characters that Pelican does not allow when defining a namespace prefix.
If you attempt to set up a namespace prefix using one of these restricted paths/characters, Pelican will fail to start with a warning that lets you know why the prefix is disallowed.